
In this case study we're going to setup a bayesian filter to automatically classify incoming mail according to the language it's written in. We'll go through the following steps:
The commands launched throughout the tutorial are run by a unix user that exists in PostgreSQL under the same login than unix, and has the rights to create a database and connect to it locally.
$ cd /usr/local/share/manitou/sql
$ createdb -E UNICODE mailb
$ createlang plpgsql mailb
$ psql -d mailb
Welcome to psql 8.0.1, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
mailb=# \i crpg.sql
[output skipped]
mailb=# insert into users(user_id,login) values(1,current_user);
Inserting our user into manitou is not strictly necessary but will let us differentiate later between tags set manually by that user and automatically by the bayesian classifier.
We're using messages from locale debian mailing-lists to get contents from different languages. After gathering mails for a few days, we get an mbox file containing 2713 messages
Chinese messages sometimes happen to be encoded in gb18030, which is not supported by default with Perl, so we install the CPAN Encode::HanExtra module.
Let's create a basic configuration file for using manitou-mdx with our database
$ cat >mdx-mailb.conf [common] db_connect_string = Dbi:Pg:dbname=mailb and import our mailbox $ perl /usr/local/bin/manitou-mdx --conf=mdx-mailb.conf --mboxfile=sample-corpus.mbox
After a couple of minutes, the import should be done and the database now contains our 2713 sample messages.
Next we run an ANALYZE in order for the db to gather some statistics
$ psql -d mailb mailb=# analyze; ANALYZE
$ /usr/local/bin/manitou --dbcnx="dbname=mailb"and create a lang top-level tag with each language as its childs, like this:
Now is the time for the tedious phase. In theory we should select all the corpus and for each mail, see what language it's written in, and set the appropriate tag.
But in our case, there's a faster way: since each of our messages contains in its header the mailing-list it comes from, we'll use that to select them and tag them in big chunks, one per language. We choose the X-Loop header line as the criteria for retrieving contents for a particular mailing-list. For example, for italian, we use the following SQL statement in the Query selection dialog:
SELECT mail_id FROM header WHERE lines ~ '\nX-Loop: debian-italian@lists.debian.org\n'
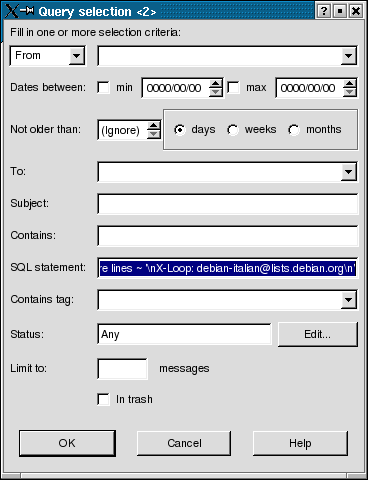
That will retrieve 346 messages from our corpus. We select them all (Ctrl+A while
the focus is in the list) and click on the "lang->italian" checkbox in the "Message
Tags" panel.
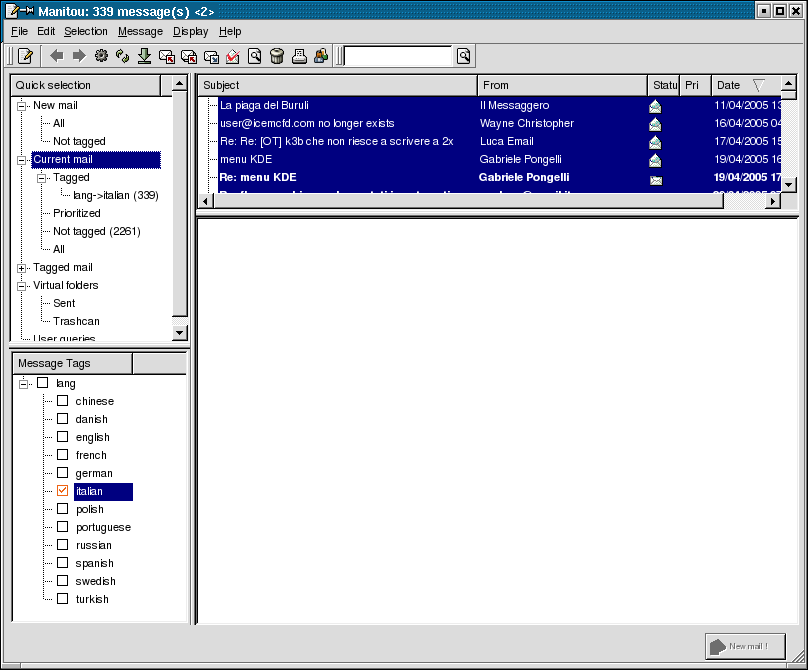
We repeat that process for every mailing-list.
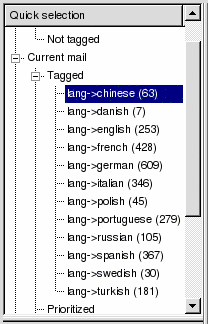
When we're done, we can see the per language distribution in the "Quick selection" panel,
or similarly, get it with a SQL query:
| User interface | SQL interpreter |
|---|---|
 |
mailb=# SELECT name, count(*) FROM tags t, mail_tags mt
WHERE t.tag_id=mt.tag group by name order by name;
name | count
------------+-------
chinese | 63
danish | 7
english | 253
french | 428
german | 609
italian | 346
polish | 45
portuguese | 279
russian | 105
spanish | 367
swedish | 30
turkish | 181
(12 rows)
|
Except for danish, it looks like the distribution of languages in our corpus is good enough.
$ /usr/local/bin/manitou-bayes-learn.pl lang 43367 entries in tags_words
Let's edit the manitou-mdx configuration file and activate the plugin:
$ cat >mdx-mailb.conf [common] db_connect_string = Dbi:Pg:dbname=mailb plugins_directory = /usr/local/libexec/mdx-plugins [me@domain.tld] incoming_mimeprocess_plugin = bayes_classifyNote that we specify a dummy mailbox because a mimeprocess plugin has to be tied to a mailbox.
Then we stop and restart manitou-mdx.
$ perl /usr/local/bin/manitou-mdx --conf=mdx-mailb.conf --mboxfile=mbox2 \ --mailbox=me@domain.tld
The first thing we check is how many messages have been auto-classified:
mailb=# select count(distinct mail_id) from mail_tags where agent=0;
count
-------
672
(1 row)
672 out of 690, that's only about 97% of classification. In theory,
the remaining 18 messages are mail for which no language scored much
higher than any other, or whose body contains too few words to compute
a score at all.
Let's have a look at these 18 messages that the filter choosed to ignore. They can be selected by the criterion that they have no tag assigned to them. (Current Mail -> Not Tagged in the "Quick selection" panel)
The outcome is:
Conclusion for the non-classified messages: the bayesian filter could do better on 8 messages, the other being either hopeless or rightly not classified.
Now let's retrieve the messages that have been categorized in a language but were not sent to the mailing-list for that language.
To automate this, we create and populate a table containing the mailing-list headers and their corresponding language tags:
mailb=# create table lgfilter (h text, lg varchar(30)); CREATE TABLE mailb=# \copy lgfilter FROM STDIN WITH DELIMITER AS '|' Enter data to be copied followed by a newline. End with a backslash and a period on a line by itself. >> X-Loop: debian-chinese-gb@lists.debian.org|chinese X-Loop: debian-italian@lists.debian.org|italian X-Loop: debian-russian@lists.debian.org|russian X-Loop: debian-user-danish@lists.debian.org|danish X-Loop: debian-user-french@lists.debian.org|french X-Loop: debian-user-german@lists.debian.org|german X-Loop: debian-user-polish@lists.debian.org|polish X-Loop: debian-user-portuguese@lists.debian.org|portuguese X-Loop: debian-user-spanish@lists.debian.org|spanish X-Loop: debian-user-swedish@lists.debian.org|swedish X-Loop: debian-user-turkish@lists.debian.org|turkish X-Loop: debian-user@lists.debian.org|english \.Then we're counting how much of the tagged messages have the "right tag":
mailb=# SELECT count(*) FROM mail_tags mt,tags t,lgfilter f,header h
WHERE mt.agent=0 AND mt.tag=t.tag_id AND t.name=f.lg
AND h.mail_id=mt.mail_id AND strpos(h.lines, f.h)>0;
count
-------
657
(1 row)
So 657 out of 672 have been correctly classified. That looks pretty good.
It should be noted that "correctness" is relative, because the fact that a message is sent to a mailing-list assigned to a particular language doesn't always mean it's mostly written in that language. Mails containing large amounts of english text can be posted to a non-english mailing-list, and conversely, the other case also marginally happens: people sometimes make the mistake to post non-english in an english mailing-list. We won't blame the bayesian classifier to get it wrong where it may actually get it right.
Let's have a look at the 15 messages that have been classified with the wrong language.
mailb=# SELECT mt.mail_id,t.name FROM mail_tags mt,tags t,lgfilter f,header h
WHERE mt.agent=0 AND mt.tag=t.tag_id AND t.name=f.lg AND h.mail_id=mt.mail_id
AND strpos(h.lines, f.h)=0 ORDER BY name;
mail_id | name
---------+---------
9253 | chinese
9437 | chinese
8902 | danish
8910 | danish
9024 | danish
9122 | danish
9241 | danish
9393 | danish
8845 | english
9416 | english
9056 | french
8838 | russian
9113 | spanish
9205 | spanish
9353 | swedish
(15 rows)
Remember that in step 4, we noted that the danish mailing-list was the one for which we had a very low number of sample messages to learn with: only 7. It's probably not a coincidence that the auto-classifier doesn't get it right with danish at this point. Apparently there are 6 mis-classifies with danish and up to 2 with other languages.
In order to retrieve these messages inside the manitou user interface, let's input the SQL sentence above into the SQL field of the Query selection (except that we remove the 2nd column from the select-list, since we only want a list of mail_id).
Reading each of these messages reveals that:
Categories for which we don't have enough sample messages (the danish language, in this case) should be excluded from auto-categorization until we have significantly more (say, 50).
After one pass of learning for 12 different languages and a corpus of 2700 messages, our first import of 690 messages shows that the auto-classifier comes up with a success rate ranging from 97% to 98% in recognizing the language.