Parallel import
Importing in parallel from a single source is really enabled in manitou-mdx since commit 6a860e, under the following conditions:
- parallelism is driven from the outside: manitou-mdx instances run concurrently, but don’t fork and manage child workers. Workers don’t share anything. Fortunately GNU parallel can easily handle this part.
- the custom full text indexing is done once the contents are imported, not during the import. The reason is that it absolutely needs a cache for performance, and such a cache wouldn’t work in the share-nothing implementation mentioned above.
The previous post showed how to create a list of all mail files to import from the Enron sample database.
Now instead of that, let’s create a list splitted in chunks of 25k messages, that will be fed separately to the parallel workers:
$ find . -type f | split -d -l 25000 - /data/enron/list-
The result is 21 numbered files of 25000 lines each, except for the last one, list-20 containing 17401 lines.
The main command is essentially the same as before. As a shell variable:
cmd="mdx/script/manitou-mdx --import-list={} \
--import-basedir=$basedir/maildir \
--conf=$basedir/enron-mdx.conf \
--status=33"
Based on this, a parallel import with 8 workers can be launched through a single command:
ls "$basedir"/list-* | parallel -j 8 $cmd
This invocation will automatically launch manitou-mdx processes and feed them each with a different list of mails to import (through the –import-list={} argument). It will also take care that there are always 8 such running processes if possible, launching a new one when another terminates.
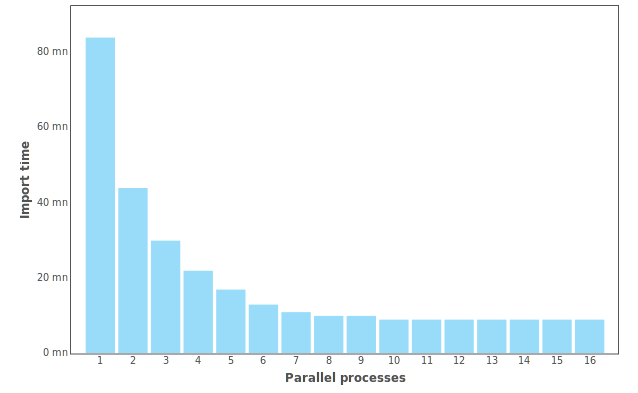
This is very effective, compared to a serial import. Here are the times spent to import to entire mailset (517401 messages) for various degrees of parallelism, on a small server with a Xeon D-1540 @ 2.00GHz processor (8 cores, 16 threads).